Концепции и типы данных PicoLisp

Перевод. Оригинал здесь
В предыдущих статьях указывалось, что PicoLisp стремится к простоте. Что же это означает на самом деле?
Если вы раньше изучали языки программирования высокого уровня, такие как
Python или Java, то вы наверняка знакомы с многими типами данных, такими
как: строки, массивы, целые числа, числа с плавающей точкой, булевы
типы... Возможно, вы никогда не задумывались, каким способом все эти
типы представлены во внутренней памяти компьютера. Откуда компьютер
знает, чему равно значение переменной или константы с именем "А", что
на самом деле означает слово function?
В современных языках программирования эти сведения непрозрачны для программиста. Об этом не нужно знать и не нужно заботиться. В этом большое отличие философии PicoLisp от других языков высокого уровня и одна из основных причин, по которым его будет интересно изучать:
В PicoLisp вам известно всё о внутреннем устройстве языка.
Так происходит потому, что внутренняя реализация очень проста и высокоуровневые конструкции напрямую соответствуют схеме данных в виртуальной машине, делая их понятными и предсказуемыми. В этом смысле picolisp похож на язык ассемблера, где программист обладает полным контролем над машиной.
В этой статье будут освещены только основные понятия. Мы не будем рассматривать такие вещи, как «смещение указателя», «переходные и внешние символы» и тому подобное. За более подробной информацией вам придётся обратится к справочной странице PicoLisp.
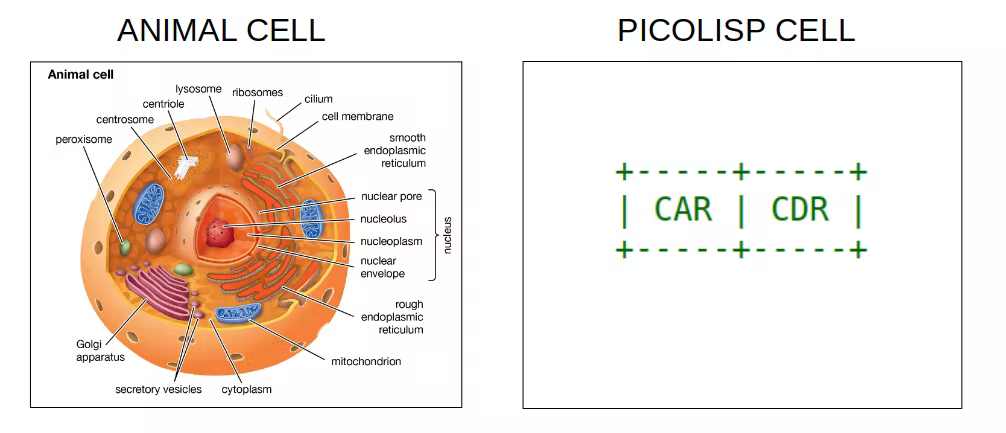
Виртуальная машина PicoLisp проще и мощнее, чем большинство современных "железных" процессоров. На самом нижнем уровне она состоит из единственной структуры данных под названием cell (переводится как клетка, хотя мне больше нравится вариант "ячейка" - прим.перев.). Это пара 64-битных машинных слов, которые в языках семейства Lisp традиционно называются CAR и CDR. Эти 64-битные слова могут представлять из себя либо числовое значение, либо адрес другой ячейки. На более высоком уровне все структуры данных состоят из этих ячеек.
Обычно нам нужно знать две вещи о данных, чтобы работать с ними:
- Где они хранятся?
- Что с ними делать?
Расположение хранится в указателе. Указатель является адресом определённой ячейки.
Вот пример 64-битного указателя на список в двоичном формате:
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx0000
Здесь X означает "неважно" (может принимать значение 0 или 1), а
последние 4 цифры обозначают тип данных. 0000 означают, что это
указатель на список.
На уровне виртуальной машины PicoLisp поддерживает:
- Три базовых типа данных - числа, символы и списки.
- Специальный символ NIL.
Числа и символы составляют подгруппу так называемых "атомов".
Ячейка состоит из пары 64-битных слов, в каждом из которых последние 4 бита означают тип данных.
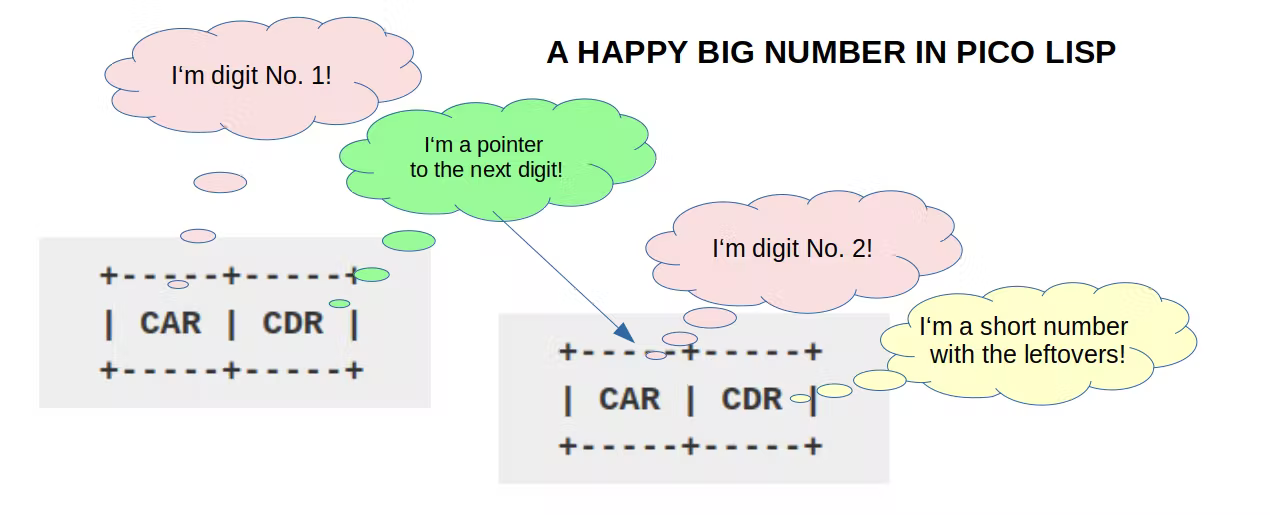
Если число имеет размер меньше 60 бит (короткое число), то оно напрямую
записывается в слово. Если же число длиннее, то нужна ещё одна ячейка,
чтобы записать его полностью. Это может выглядеть примерно так:
 Как уже говорилось, последние четыре
бита слова указывают на тип содержащихся в нём данных. У короткого числа
это
Как уже говорилось, последние четыре
бита слова указывают на тип содержащихся в нём данных. У короткого числа
это S010, то есть второй с конца бит равен 1, у "длинных" чисел это
S100, то есть единице равен третий бит с конца. Четвёртый бит с конца
(S), используется для обозначения знака числа. У положительных чисел он
равен 0, у отрицательных 1.
-Двоичное представление числа 10 - 1010. -Тип данных - полржительное
целое число, то есть последние 4 бита будут выглядеть так: 0010.
-Остальные знаки слова будут равны нулю:
0000000000000000000000000000000000000000000000000000000010100010
Теперь давайте поговрим о символах. Символы - более сложный тип данных, по сравнению с числами. У каждого символа есть значение, иногда есть имя и произвольное количество свойств. Символ распознаётся интерпретатором, если выглядит вот так:
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx1000
То есть старший из четырёх бит, отвечающих за тип слова, равен 1, остальные - 0.
Пример: давайте возьмём переменную с именем "A" и значением 7. Символ "A" представлен числом 65 в кодировке ASCII. Ячейка, которая содержит данный символ, будет выглядеть вот так:
+-----+-----+
| 65 | 7 | Cell of symbol named "A" with value 7
+-----+-----+
Как видите, голова ячейки (CAR) содержит имя символа, а хвост (CDR) -
его значение (которое позже будет обозначаться VAL.
Как вы могли заметить, в PicoLisp нет строкового типа данных. В PicoLisp строки являются символами. Если мы объявим переменную с именем "name" и значением "Mia", то пременная будет выглядеть вот так:
+------+-----+
|"name"| | |
+------+--+--+
|
V
+------+-----+
| "Mia"| |
+------+-----+
("name" and "Mia" should be ASCII-representations).
У нас есть символ с именем "name", вместо значения у которого - указатель на другую ячейку, с символом "Mia".
Теперь давайте рассмотрим более сложный пример - символ, у которого есть свойства. Свойство - это пара ключ-значение. В противоположность символам ячейка, хранящая свойство, содержит в голове (CAR) значение (VAL), а в хвосте (CDR) ключ (имя).
Вот пример символа A со значением 7, у которого есть свойство n со
значением 3:
+-----+-----+
A | | | 7 |
+--+--+-----+
|
V
+-----+-----+
| | | 65 | ASCII "A" = 65
+--+--+-----+
|
V
+-----+-----+
| 3 | | |
+-----+--+--+
|
V
+-----+-----+
n | 110 | / | ASCII "n" = 110
+-----+-----+
'/' represents a pointer to the symbol NIL.
Символ A до сих пор содержит в CDR значение 7, но CAR ячейки с
именем символа теперь указывает на ячейку с ключом свойства, которая
затем указывает на ячейку со значением ключа. Пары ячеек, отвечающие за
ключ/значение, образуют цепочку, в которой каждый CDR (хвост) указывает
на следующую ячейку, а в хвосте последней содержится специальный символ
NIL.
Среди типов данных PicoLisp есть один специальный символ - NIL. У него
много функций, среди которых:
- Представлять булево значение "false" (ложь)
- Представлять значение "Not a Number" (не число)
- Обозначать конец списка
- Обозначать пустой список
- Обозначать неопределённую переменную
- ...
NIL присутствует в системе в единственном числе. Каждый раз, когда вы
видите его в коде - он указывает на одну и ту же ячейку.
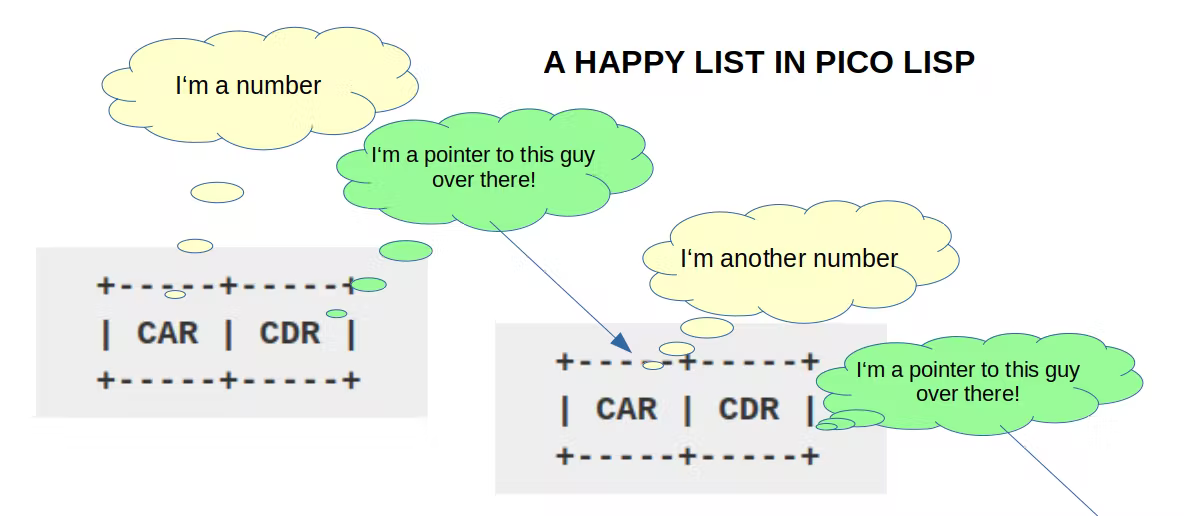
Списки явояются базовым типом для всех сложных типов данных, таких как
деревья, массивы, стеки и так далее. Как и у больших чисел, CDR каждой
ячейки указывает на следующую ячейку цепочки.
Мы рассмотрели большие и малые числа, списки, символы, включая строки и символы со свойствами, которые в некоторых языках программирования называют объектами. Но как насчёт всего остаоьного?
- Булевы типы. Здесь всё просто. Есть
NIL, являющийся представлением значения "ложь". Всё, что не является ложью, является истиной (T). Нет нужды в ещё одном типе данных. - Как насчёт функций? В них нет ничего особенного. Это либо указатель на адрес в памяти, где расположен управояющий код, либо список. Вы увидите множество примеров последнего в дальнейшем, представление функции списком - один из основных принципов функционального программирования в PicoLisp.
- Как насчёт массивов? В качестве массивов в PicoLisp используются списки. В PicoLisp есть специальные массивоподобные списки, но о них будет написано отдельно.
Итак, в PicoLisp есть три базовых типа данных: числа, символы и списки. Все они построены из ячеек (CAR+CDR в терминологии Lisp). Сложные типы данных создаются с помощью ссылок на другие ячейки, располрженных в CAR и/или CDR.
Этой теории должно быть достаточно, чтобы начать понимать PicoLisp. За более подробной информацией, не раскрытой в данной статье, обратитесь к справочному руководству.